該模型的基本思想就是利用交易量分佈的記憶性,將每個交易日固定時間段的交一易量佔全天交易量的比例按照加權平均的方法前推,得到一個新的交易量分佈。
首先將交易日等分爲固定數量的N個區間。區間的長度不能太長也不能太短,太長的區間會使模型顯得比較粗糙,而且區間操作的不確定性也會增加;太短的區間又因爲嗓音等因素而使得預測模型不可靠。基於上述考慮,本節的討論中取N=48,每個區間的長度爲5分鐘。
假設利用前L個交易日的歷史數據來預測接下來一天的交易量分佈。需要預測交易量分佈的日期記爲L,歷史交易日按由遠及近的原則分別記爲t1,…,tL。對於日期T=ti,日內交易量分佈爲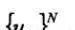 ,其中Uik表示ti天的第k個區間內的交易量佔全天交易量的比例。
,其中Uik表示ti天的第k個區間內的交易量佔全天交易量的比例。
採用如下移動加權平均方法來預測新的交易量分佈:
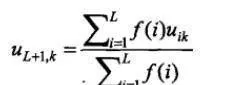
其中,f(i)表示對應於ti的加權係數。
不同的加權係數體現了對歷史數據的不同看法。簡單移動加權平均平等對待所有的歷史數據,而線性加權平均則將更多的權重放在最近的歷史數據上。
如圖8-1所示是利用20個交易日曆史數據,線性加權平均得到的2010年1月11日的武鋼股份(SH600005)的交易量分佈與實際交易量分佈的對比。
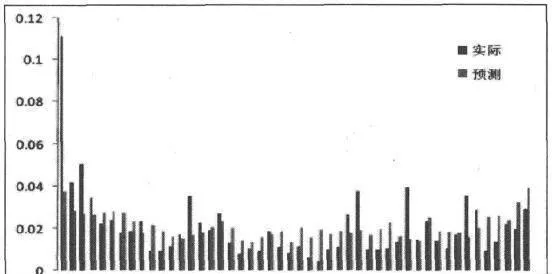
圖8-1 移動平均預測交易量與實際交易量對比
計算可得二者的線性相關係數爲0.52,意味着預測結果和實際結果之間具有較強的相關性,即預測有一定的作用。對其他數據進行分析可以得到類似的結果,但是相關性波動較大。這是由於影響日內交易量分佈的因素太多,突然的大宗成交等無規律的行爲導致了分佈的異常,而這也將直接影響到標準VWAP策略的執行效果。