该模型的基本思想就是利用交易量分布的记忆性,将每个交易日固定时间段的交一易量占全天交易量的比例按照加权平均的方法前推,得到一个新的交易量分布。
首先将交易日等分为固定数量的N个区间。区间的长度不能太长也不能太短,太长的区间会使模型显得比较粗糙,而且区间操作的不确定性也会增加;太短的区间又因为嗓音等因素而使得预测模型不可靠。基于上述考虑,本节的讨论中取N=48,每个区间的长度为5分钟。
假设利用前L个交易日的历史数据来预测接下来一天的交易量分布。需要预测交易量分布的日期记为L,历史交易日按由远及近的原则分别记为t1,…,tL。对于日期T=ti,日内交易量分布为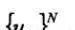 ,其中Uik表示ti天的第k个区间内的交易量占全天交易量的比例。
,其中Uik表示ti天的第k个区间内的交易量占全天交易量的比例。
采用如下移动加权平均方法来预测新的交易量分布:
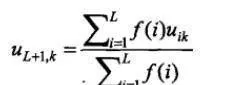
其中,f(i)表示对应于ti的加权系数。
不同的加权系数体现了对历史数据的不同看法。简单移动加权平均平等对待所有的历史数据,而线性加权平均则将更多的权重放在最近的历史数据上。
如图8-1所示是利用20个交易日历史数据,线性加权平均得到的2010年1月11日的武钢股份(SH600005)的交易量分布与实际交易量分布的对比。
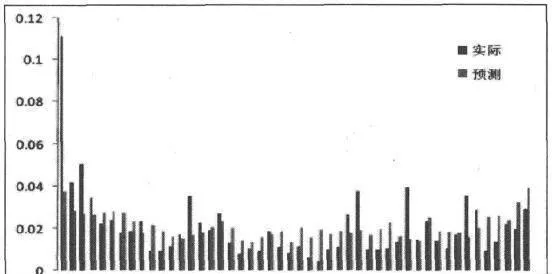
图8-1 移动平均预测交易量与实际交易量对比
计算可得二者的线性相关系数为0.52,意味着预测结果和实际结果之间具有较强的相关性,即预测有一定的作用。对其他数据进行分析可以得到类似的结果,但是相关性波动较大。这是由于影响日内交易量分布的因素太多,突然的大宗成交等无规律的行为导致了分布的异常,而这也将直接影响到标准VWAP策略的执行效果。